

Building a Data Hub: Microservices, APIs, and System Integration at the Art Institute of Chicago
Illya Moskvin, Art Institute of Chicago, USA, nikhil trivedi, Art Institute Chicago, USA
Abstract
A common problem museums face is fragmented data across a variety of systems. Ad hoc integration is often costly, fragile to institutional change, and limiting to project scope. To address these issues, the Art Institute of Chicago has built a data hub: an intermediary system that collects data from disparate sources, harmonizes it, and makes it searchable through a single, normalized API. Here, we will discuss the architectural and collaborative considerations involved in building such systems, some techniques for doing so, and the strategic and tactical benefits they can bring.Keywords: api, data, integration, normalization, architecture, standardization
Introduction
A common problem faced by organizations in many sectors is fragmented data across a variety of systems. Museums are no exception. Within a single institution, it is common to find multiple content management systems, for collections, digital assets, institutional libraries and archives, membership, conservation, websites, apps, and various one-off projects amassed over the years. Each of these systems contains data that could be of great use when planning new projects, but the inherent difficulty of building interfaces to each system involved tends to prematurely curtail project scope.
Once extracted, data is often found to be inconsistent and disconnected, requiring cleaning and interlinking efforts that may need to be repeated for each project. Looking beyond the institution, external data authorities, datasets from other institutions, as well as monitoring and analytics services contain information that could be leveraged to enhance internal datasets, but established departmental responsibilities often mean that these resources remain untapped. Ultimately, these limitations can result in public-facing products and user experiences that do not meet their full potential.
To address these issues, the Art Institute of Chicago has built a data hub: an intermediary system that collects data from disparate sources, harmonizes it, and allows it to be queried through a single, normalized API. At the time of writing, our data hub powers our website and mobile app, with in-gallery interactives soon to follow, and is expected to be the data broker for all of our future public-facing projects.
In this paper, we present institutional circumstances that prompted the creation of our data hub, share the design goals behind the project, and describe the architecture we created in response to these requirements. We discuss some of the benefits such systems bring, as well as some of the challenges we encountered, and close by sharing several ideas and improvements we look forward to implementing in the future.
Background
Three years ago, the Art Institute of Chicago began a major website redesign project. Among the goals of this redesign was a desire to increase discoverability by exposing related content and integrating our collections throughout the site. Internal search was given a high priority, with a secondary goal of ensuring that the search experience remained consistent across our website and mobile app, regardless of where the data originated.
The institution used this project as an opportunity to audit all of our digital properties both in terms of technology and design. These findings prompted a unification effort. A decision was made to create a reusable design system and to develop an intermediary data repository that could normalize data and deliver it in a consistent way to all of our products.
Supporting this decision were a number of logistical factors such as timing, team structure, and ownership. The institution created an in-house development team to maintain and improve the new website. The initial development of the website, however, was to be done by a third-party vendor (AREA 17). After our in-house Web team was formed, there was a period of ten months before our partner was due to begin development, and our Web team could not take ownership of the codebase until development was complete. Concurrently, our mobile app was to be updated to its second version, with artwork search slated to be a major new feature.
Although these circumstances may be unique to our institution, this strategic approach is transferable. Engaging in the development of the data hub allowed us to make headway on functional requirements ahead of schedule, freed our partners to focus on feature development rather than costly integration, and formed a repository of institutional technical knowledge that would, in turn, enable an internal team to audit vendored work. Likewise, our data hub would not be developed in a vacuum. We had real projects with concrete business requirements against which to test our architectural approach.
Requirements
From our audit, we identified about a dozen systems from which we would likely need to import data for the website project. These included collections (CITI via 4D), digital assets (LAKE via Fedora), library (Alma and Primo), archives (CONTENTdm), digital catalogues (OSCI Toolkit), and mobile (Drupal), as well as shop, ticketing, and membership. We needed to pull data from our old website (Drupal) to aid in the migration, as well as plan for interfacing with our new website (Laravel). To enhance this data, we set an early goal to pull from Google Analytics and Getty’s ULAN, with tentative plans to explore other external datasets. Much of our initial work focused on researching the outbound capabilities of these systems and designing interfaces to extract their data.
As designs for the new website solidified, we turned our thinking more towards translating them into technical requirements for an outbound API. Concrete needs were identified. Scholarly publications, microsites, educational materials, and other multimedia needed to be surfaced on artwork pages. Full-text search, term filters, and autocomplete suggestions were essential to the collection search experience. Content editors required the ability to search for and embed related content throughout the site. Global search, too, needed to query across a variety of content types when retrieving results.

Our API needed to support not only full-text search, but also general queries, with flexibility similar to that of traditional SQL databases. We needed to provide our consumers the ability to filter data by field values and relationships, aggregate to determine filter options, and issue phrase or keyword queries that would return matches ordered by relevance. Sometimes, we would have to meet these needs concurrently, when a full-text search was issued within a filtered set, returning results alongside aggregations for further faceting.
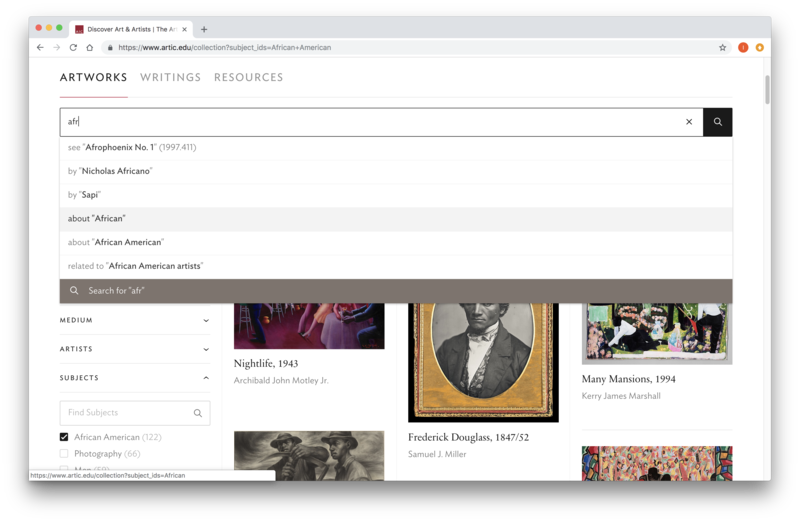
At the same time, we needed to retain some control to influence the order of results and fulfill stakeholder expectations in a way that would be palatable across a variety of products. We also needed to balance flexibility against security to reduce risk and keep open the option of offering the API for public use. All of this had to be done in a manner that was maintainable and reduced duplication of work as much as possible.
Design Goals
Early on in the project, we set a number of design goals for the data hub. These guidelines were meant to limit scope, allowing us to move quickly and incrementally within a living ecosystem. Although our goals evolved over time, they have served us well and continue to inform the project.
Our data hub would be public-facing and store only publicly-accessible data. We could thus defer the potentially complicated topic of authentication until later. This decision mitigated risk and allayed internal concerns about hosting the data hub using cloud infrastructure. It eased the process of opening our API to the public and allowed us to establish an early expectation that data coming to us from upstream systems should be pre-vetted for public access. Although this is changing, it gave us valuable time to focus efforts elsewhere early on in the project.
Our data hub must not keep any exclusive, unique data. If all the data in the data hub was to be removed, or its servers destroyed, we should be able to regenerate it using data from upstream systems. (Granted, this process may result in significant downtime, so it is not something we would normally do from scratch.) If there is ever a need to store new data permanently, then a separate system of record should be created. Emphasizing this “rebuild from source” approach prompted us to prioritize speed in our import processes, which in turn eased debugging of data transformations and ensured that we did not become a bottleneck in the publication pipeline.
Minimizing modifications to source systems was another early goal. With vendored and legacy source systems, pursuing modifications could be costly and impractical. For systems that were developed in-house, keeping our effort footprint low was an important investment as newcomers to the ecosystem. Any modification requests would have to come from data hub consumers: the data hub would serve as an arbiter to ensure that upstream systems delivered data in a clean fashion, but for some time, it would avoid instigating upstream change for its own sake. This approach pushed us to develop novel solutions for data extraction. Once the data hub established itself, we took advantage of projects that were already in the works to request changes that would stabilize our imports.
Architecture
Broadly, the data hub follows a hub-and-spoke model. It is comprised of multiple Web services. There are several microservices acting as the spokes, whose primary purpose is to extract data from source systems. All of these small data services feed into a central hub service, which we call the data aggregator. The aggregator offers its collected data via outbound APIs to consumers of the data hub.
Briefly, we would like to explain some of the key terminology used in this paper, and in this section in particular. We refer to components of the data hub as “services” rather than “applications” because these systems are not meant to provide an experience to users directly. Instead, they perform specialized operations on data and interface with other systems. In contexts like the data hub, small services such as those that comprise the spokes of our architecture are often referred to as “microservices” or “data services.” In this paper, we use these two terms interchangeably. The aggregator at the core of the data hub is also a service, but a relatively large one, with many responsibilities.
To facilitate communication between software, we use Application Programming Interfaces (APIs). Essentially, APIs are methods of providing data using predictable, normalized formats in ways that are easy for other software to use. Each of our microservices communicates with the aggregator using APIs, and the aggregator itself provides APIs for data hub consumers. We use the JSON format as our primary means of communication, and our services are accessible via HTTP/S. As such, we refer to them as Web services. We consider upstream source systems and the teams responsible for them to be our providers, and downstream systems we supply with data, our consumers.
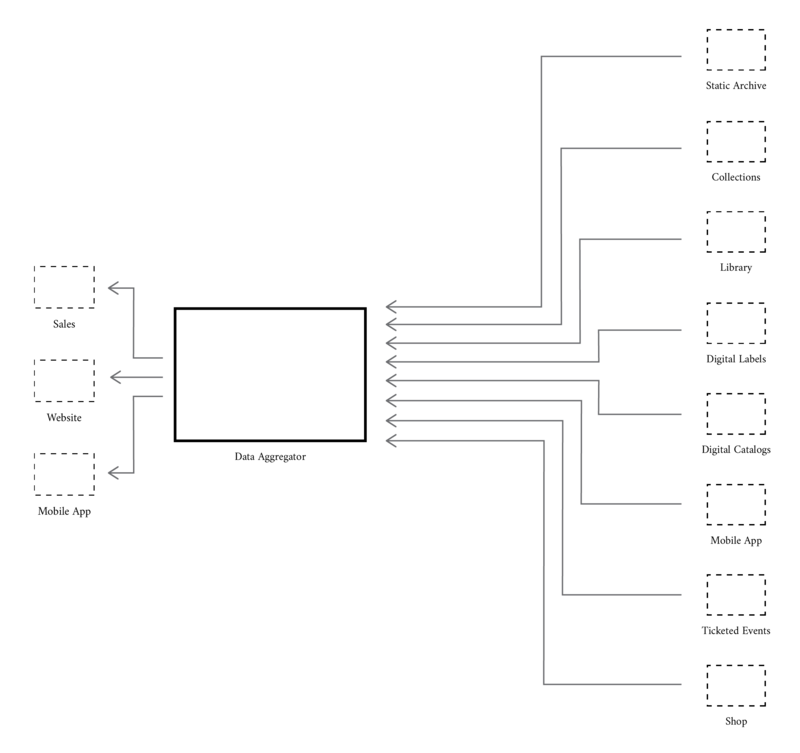
The Spokes: Data Services
Each data service is a small program with a specific responsibility. We classify most data services as “extractors,” each of which acts as a layer between a source system and the aggregator, retrieving, normalizing, and cleaning data from source systems before it makes its way to the core. Other data services are “enhancers,” which interface with the aggregator to add data that was absent in the system of record. For example, one data service performs a variety of image analysis tasks and another matches artists from our collection system with records in the Getty’s ULAN.
It may also be useful to classify data services in terms of techniques used to retrieve data. Broadly, we differentiate between “scrapers” and “transformers.” Choice of technique depends on the capability of each source system to output data and the viability of making that process more reliable. Most of the time, upstream systems have either no API or one that is flawed in some way that makes it unusable directly. In these cases, various scraping techniques must be employed to extract data from the system and replicate it to a local database, which the microservice can use to offer an API that has all the features needed for transferring data into the aggregator. For example, we employ scraping techniques for data dumps (ticketing), ePubs (OSCI), and APIs (CONTENTdm, etc.). Scraping websites in this manner is also viable, but may run a greater risk of breaking changes.
Conversely, our collections data service is a mere transformer. It accepts import queries from the aggregator, transforms them into queries to the collection system’s API, and transforms the response into something that more closely matches our desired schema. Nothing is stored locally. This approach was possible because the upstream system already had an API with all the features we needed to extract its data on demand. In such cases, we found that having a microservice in place can still be useful to mitigate upstream changes and compartmentalize extensive transformation logic.
Lastly, we can discuss microservices in terms of their interfaces, or how they transfer data to each other. Broadly, we can think of this as “pushing,” “pulling,” and “messaging.” Pulling is the simplest technique: a consumer fetches data from a provider, typically on a timed basis. The consumer decides when data transfer happens and from where it will be retrieved. The provider must offer an API for reading its data. Pushing builds on this in an effort to make data transfer more timely. The consumer must offer an API that accepts data, and it is the provider’s responsibility to push data to the consumer. Security demands more consideration when pushing is employed. Messaging is the most complex approach of the three. It introduces an intermediary system to the push-pull equation. The provider pushes data to the messaging system, and the consumer retrieves messages from it. This can be valuable when asynchronous communication is a priority, or when multiple consumers need to digest data from the same provider.
In this regard, our data hub is quite simple. All of our services (including the aggregator) use pulling exclusively. Creating a read API is often one of the first steps when developing data providers, and writing imports to pull from such APIs is a natural progression. Generally, all data travels inwards to the aggregator, where it is replicated locally. Likewise, our microservices communicate only with the aggregator, not with each other. Such factors made investment in alternate techniques unappealing thus far, though we may explore them again if the need arises. We found that keeping things simple here makes data transfer easier to debug, but with a proper monitoring solution in place, each of these approaches is viable.
The Hub: Data Aggregator
At the core of the data hub is a program we call the data aggregator. The aggregator imports information from all data services, forms interrelations across systems, and indexes data into a search engine. It uses a relational database (MySQL) as its primary datastore and Elasticsearch as the search engine. Most importantly, it handles all outbound data for the data hub. If any consumer wishes to use our data, they must in some way interface with the aggregator. Our current architecture discourages consumers from interfacing with microservices directly to ease change management. The aggregator currently offers outbound support in the form of CSV data dumps and two REST APIs: one connected to the database, and another to Elasticsearch.
This thin search client is arguably the most exciting part of the aggregator. It is essentially a wrapper around Elasticsearch. It accepts Elasticsearch DSL-style queries, transforms them with our institutional business logic, sends them to Elasticsearch, and transforms its response before returning it to the user. This allows us to support full-text search, faceting, and filtering.
A common issue with custom REST APIs is that they become susceptible to leaky abstractions once requirements grow in complexity. Much engineering effort could be spent to simplify and obscure underlying technologies, but as more demands are placed on the API, these abstractions become difficult to maintain. Instead of trying to abstract away the underlying search engine, we expose most of its read interface to the consumer. Although this results in complete vendor lock-in, we found that the power offered by Elasticsearch’s DSL is worth the trade-off. Its JSON-based RESTful API is well-documented, making it easier to onboard consumers, and fits well with our architecture.

This approach prompts a question: why put a thin search client in place, instead of having consumers query Elasticsearch directly? Being able to transform incoming queries with our business logic is the biggest advantage. It reduces effort duplication among our consumers, codifies our consultations with stakeholders, and ensures a consistent experience across multiple products. For example, for each resource type, we can specify which fields should be targeted by default for full-text search, as well as what weight should be given to each field when determining relevancy. We can also wrap incoming queries in clauses that tweak result order, e.g. weighing for popularity using analytics data.
Security is another advantage granted by the search client. Elasticsearch has a permissive API with no access control mechanisms. Having a search client gives us more fine-grained control than a firewall or reverse-proxied authentication would allow. It lets us be selective about which queries we accept, preventing administrative queries that would affect system integrity. It gives us a place where we can restrict access to specific resources, which will become useful as we move towards opening our API to the public.
Microservices vs. Monoliths
The aggregator is the monolith to our microservices. It has much of the same functionality as a data service, particularly in regards to data cleaning and normalization. In a few cases, it imports data from source systems directly, without the use of an intermediary microservice. It is by far the most extensive service in the data hub, in terms of both responsibility and lines of code.
How, then, do we decide when to create a microservice for a given functionality? Several factors inform this decision. If the code needed to extract data from a source system exceeds a certain level of length or complexity, we may consider compartmentalizing it into a microservice. If some functionality demands a disproportionate amount of computing resources, we might move it to a microservice for flexibility during deployment. If some upstream system has strict security requirements, we might access it using a microservice to reduce the attack surface. Most of the time, these factors are evident before development on a given feature begins, but refactoring features from a monolith into a microservice is also a safe approach.
We created a foundation package that is used by all of our services, including the aggregator. All of our services are built at least in part using the same language (PHP) and framework (Laravel). Having a shared foundation allows us to reduce code duplication among services. Among other things, it ensures that all microservices have a consistent outbound API schema, which eases the process of writing import code for the aggregator. We are gradually refining this foundation. Although our data hub was never meant to be plug-and-play, we can see other institutions using the foundation package to build their own microservices, or even their own data hub.
Benefits
Having a data hub benefits institutional workflows. Strategically, data hubs provide consistent APIs with clean and interrelated data, which reduces effort duplication, mitigates costs for future projects, facilitates reports and analytics, and buffers institutional change. Tactically, data hubs offer a measure of agility for working around limitations in upstream systems and provide avenues for integrating experimental work for wider use.
Data hubs offer an opportunity to clean, normalize, and interrelate data. Upstream data is often messy, either due to errors in data entry or automated transformations gone awry. Upstream systems might lack adequate APIs, requiring scraping and subsequent cleaning. Data coming from disparate systems is often disconnected and follows different schemas. Whatever the case might be, it is useful to have an intermediary system to clean and interconnect that data and output it via a consistent, flexible API. Without the data hub, each consumer would have to clean their own data, duplicating effort. For institutions interested in pursuing not only application development, but also data science and machine learning, this can provide a valuable head start, given how time-consuming data cleansing tends to be for such projects. Ideally, however, data cleanup should be done in the source systems, and doing otherwise can increase long-term risk.
Data hubs create space for shared business logic. For example, house style may dictate that certain fields (e.g. dates) must be transcribed in specific ways, or maximum image size might be dependent on copyright restrictions for certain artworks. If upstream data providers decide that implementing this display logic is not their responsibility, then typically, it would be up to each data consumer to reimplement it. With a data hub in place, such logic can be implemented there, and the results exposed via a field in its API. Each consumer would need only to reference the field for display. This reduces code duplication across the organization.
Although building a data hub is a considerable investment, it saves cost on other projects. With shared business logic in place, there is less need to reimplement functionality. Data generated in siloed or temporary projects can easily be extracted for reuse elsewhere via microservices. Having a consistent API in place reduces onboarding time, and the ready availability of data creates opportunities for feature development in areas that might have otherwise fallen outside project budget. Expensive vendor time can be channeled towards feature development rather than costly integration. Overall, data hubs reduce costs for future projects.
Like other data warehousing solutions, data hubs offer an integrated repository for generating reports and running analytics. While reporting was not an initial focus of our data hub, it could be a strategic consideration for undertaking such a project in other organizations. As we restrict our data hub to public data, most of the reports we run serve the needs of external applications. If reporting is given higher priority, security and authentication may need to be elevated as well so as to draw in and provide access to a wider range of data.
Data hubs both buffer and facilitate institutional change. When an upstream system undergoes updates, the data hub’s transformers mitigate changes to its outbound API, minimizing the impact on downstream data consumers. This can reduce the burden on both upstream and downstream teams. Likewise, the data hub constitutes an institutional repository of knowledge on data extraction. When a system has to be sunsetted or replaced, the data hub can aid in the migration, and its team can provide oversight to ensure the needs of their consumers are met. As technological responsibility is shifted between teams or applications within the institution, the data hub acts as both a fulcrum and a buffer to ensure operations remain unaffected.
Data hubs can grant a certain measure of agility. Oftentimes, downstream projects require data that primary upstream systems are unable or unwilling to provide. Without an intermediary, it would be the responsibility of that project to procure or produce that data. Having an established data infrastructure in place opens more options. We can ferry data between projects, create microservices to enhance data with additional processing, and import external datasets, which may otherwise go untapped due to established lines of responsibility. To consumers of our outbound API, data appears consistent regardless of its origin. Data hubs can thus introduce another level of effort sharing and facilitate collaboration within an institution with a siloed or otherwise complex organizational structure.
Lastly, data hubs provide structure for experimentation. Although our data hub is a system integration project, we are an experience design team. Experimenting with creative technical solutions to provide a better user experience is part of our directive. Unfortunately, such experiments can result in projects that are siloed, temporary, or limited in scope. Having a data infrastructure in place helps us formalize these experiments, broaden their scope, and bring them into wider use. For institutions with focus on exhibition interactives, data hubs can enable their development, as well as recycle some of their effort for other projects. For us, providing paths for integrating experimental work into the data pipeline is a high priority as we move to open our API to the public.
Challenges
Although we saw many benefits from building a data hub, this project has not been without its challenges. While most can and have been solved through communication with stakeholders and adjustments of architecture, some are perennial. Broadly, these ongoing challenges include performance, support, scope, and change management.
Performance of our outbound API remains a concern. Our website is the biggest consumer of our API in terms of traffic. Much of its functionality is powered by the data hub. Periods of high traffic on the website can cause congestion and dropped connections between it and the data hub. We mitigated this through server infrastructure and caching, but we expect that we will always keep exploring improvements to our architecture and server configuration with the aim to reduce network response time and facilitate connection reliability. Additionally, while caching should ideally be implemented by all API consumers, we must be mindful to balance cache times against stakeholder expectations of how quickly data appears to update on the website and other downstream systems.
As owners of the institution’s outbound API, we are often the front line for requests and issue reports pertaining to data. When some piece of data displays incorrectly downstream or some record fails to feed through, the data hub is the first place stakeholders look, even if the issue originated in an upstream system. With a complex data pipeline in place, it can be difficult for data maintainers to trace its path through the institution’s systems. Here, the consistency of the data hub’s API works against us, effectively turning it into a black box, and the transformations we put in place for data cleansing can create confusion as to what is and is not affected by such automation. Working on the data hub has given us some measure of familiarity with the internal workings of upstream systems, which further encourages stakeholders to approach us for advice. When working with complex or unreliable upstream systems, debugging data issues thus becomes a considerable time sink. We are mitigating this by improving our monitoring infrastructure and communicating the data debugging process to build trust in our system.
Lastly, we are gradually moving towards importing and outputting only what is needed by downstream systems. Once an extraction method is in place, it can be tempting to use everything a system offers. This is something we struggled with during early development before requirements solidified. Over time, we found that it is easier to add new things than to take away old ones. When a project is in its early stages, overextending can raise the effort required for refactoring. Defining an outbound schema that is too broad risks breaking changes when we feel the need to update API conventions for a cleaner overall experience. Data that is not in use by downstream systems is at risk of becoming stale or corrupt: less upkeep time is devoted to data that has no consumers to audit it and provide oversight. While we rarely deal with such issues at the present time, it is something we are prioritizing as we move towards opening our API to a wider audience. We are exploring several techniques for change management, including API versioning and contract-based testing.
Future Improvements
Although our data hub has fulfilled its initial goal of supplying data to our public properties, our work on it continues. We alluded to several ideas for future improvements throughout the paper, but some are worth elaborating on a more general level. Broadly, our areas of interest include refactoring architecture, data monitoring, exploring new data sources, data enhancing, and public engagement.
While refactoring eases code maintenance, we also view it as an essential step in improving reliability and performance. Creating a consistent codebase allows us to in turn ensure consistency in our imports and API. Modularizing code into packages facilitates its reuse and provides flexibility in shifting responsibilities among systems. For example, we are exploring the possibility of refactoring our search client into a library. Our website is built using the same framework as the data hub, so we can import the search client package into it with minimal adjustments. This may improve performance by allowing it to communicate with Elasticsearch directly instead of via the aggregator, saving expensive network hops while retaining all business logic necessary for query transformations. The aggregator would then deploy an instance of the search client library to serve the needs of other API consumers.
We want to formalize our data debugging experience into a data monitoring subsystem. Some data cannot be cleaned automatically, but in certain cases, it is possible to alert content editors of potential issues. Examples include identifying broken links, undersized images, malformed dates, and relationships to non-existent content. These issues reoccur as content changes. Having a system that audits data on an ongoing basis may prove valuable.
We would like to import data from more sources. Few internal sources remain untapped, but we are excited to explore the possibilities offered by external datasets and APIs. Some items of interest include Wikidata, Google’s Knowledge Graph, and the Getty’s Vocabularies. We are already using the Getty’s ULAN to connect agent records between our institution’s collection and library systems. There are ongoing conversations in regards to what extent external data should be displayed to the user. Setting up workflows for stakeholders to approve or flag issues in inbound external data is an interesting challenge.
Automated data enhancement is another priority. For example, we created an image data service. Here, we can download images from our DAMS and enhance them with additional data, such as perceptual hashing, color extraction, and interest point detection. This should allow us to offer features such as reverse image search, search by drawing, and search by color. Generally, computer vision is one of our focus areas for near-term experimentation.

We want to further public engagement on a technical level. Our data hub has been open source on GitHub since the start, and we want to invite public code contributions as it moves out of beta. At the time of writing, we are moving toward providing data dumps and opening our API to the public. As we refactor the data hub, we want to refine its foundation package for potential reuse by other institutions. Lastly, we want to explore the possibility of offering opportunities for virtual volunteering.
Conclusion
Building a data hub is as much a human endeavour as it is a technical one. Conway’s Law states, “Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure” (Conway, 2012). Developing a data hub can require close coordination with both upstream data providers and downstream data consumers, but the end result reduces ongoing effort for both parties and prevents organizational divides from impacting the user experience of public-facing projects.
We garnered many benefits from building our data hub and look forward to its continued development, as we move down our roadmap towards opening its API to the public. In the meantime, we invite readers to peruse its source code on GitHub (https://github.com/art-institute-of-chicago?q=data).
Further Reading
Conway, M. (2012). “Conway’s Law.” Last updated August 4, 2012. Consulted February 18, 2019. Available at: http://www.melconway.com/Home/Conways_Law.html
Feldman, D. (2018). “Data Lakes, Data Hubs, Federation: Which One Is Best?” Last updated October 9, 2018. Consulted February 18, 2019. Available at: https://www.marklogic.com/blog/data-lakes-data-hubs-federation-one-best/
Hohpe, G. (2003). “Hub and Spoke [or] Zen and the Art of Message Broker Maintenance.” Last updated November 12, 2003. Consulted February 18, 2019. Available at: https://www.enterpriseintegrationpatterns.com/ramblings/03_hubandspoke.html
Hohpe, G., & Woolf, B. (2003). “Introduction to Messaging Systems.” Originally published October 20, 2003. Consulted February 18, 2019. Available at: https://www.enterpriseintegrationpatterns.com/patterns/messaging/MessagingComponentsIntro.html
Sturgeon, P. (2015). Build APIs You Won’t Hate: Everyone and Their Dog Wants an API, so You Should Probably Learn How to Build Them. Self-published.
Syn-Hershko, I. (2017). “Don’t Be Ransacked: Securing Your Elasticsearch Cluster Properly.” Last updated January 12, 2017. Consulted February 18, 2019. Available at: https://code972.com/blog/2017/01/107-dont-be-ransacked-securing-your-elasticsearch-cluster-properly
Cite as:
Moskvin, Illya and trivedi, nikhil. "Building a Data Hub: Microservices, APIs, and System Integration at the Art Institute of Chicago." MW19: MW 2019. Published January 15, 2019. Consulted .
https://mw19.mwconf.org/paper/building-a-data-hub-microservices-apis-and-system-integration-at-the-art-institute-of-chicago/