

Cultural Collections as Data: Aiming for Digital Data Literacy and Tool Development
Liz Neely, Georgia O'Keeffe Museum, USA, Anne Luther, Center for Data Arts, The New School, USA, Chad Weinard, Independent Consultant, USA
Abstract
With the advent of web browsers in the late 1990s and early 2000s, the cultural sector made huge breakthroughs in collections research and access as museums and other cultural institutions began publishing their collections information on the Web. But several problems have continued to thwart the next revolution in re-thinking the broad ways in which museum collections research can encourage use of digital collections. Data ownership, authority in data validation and terminology, technological progress, a digital divide, data ethics, and algorithmic bias are a selection of discourses that need to be considered in a long-standing history of digitizing cultural collections to create a digital literacy of museum data. Considerate decisions about the development of new tools that allow museums to more easily share, visualize, comprehend and analyze cultural data need to reference these discourses in their extensive design. What are the possibilities for learning from digital humanities and promoting use of museum digital collections as data? How do we go beyond providing APIs and other open data sets to promote a transformation for how these data are used for exploration, computational research, and creative re-generation? In this forum, panelists will survey current practice and learn from the aligned discipline of digital humanities for a closer look at using collections as data. How can museums act to fundamentally change the way we think about publishing and producing tools for generating new knowledge? What are the ways in which museums can acknowledge, examine, and provide access to interrogate ethical uses of data and cataloging practices as part of the decolonization of museums? Panelists will share concepts and work from the digital humanities, the field of interactive data visualization, examples from the panelists’ own projects with museums and other emerging collections as data usage in the cultural heritage field.Keywords: data visualization, creativity, data science, open data, tool development, digital literacy
Introduction
Museums collect, produce, and share a significant amount of data concerned with the social, cultural, and economic contexts for the circulation, exhibiting, and storing of cultural heritage and other museum objects. A museum database stores information like a log book of a living organism—some information are administrative, some research-based and others trace the life of an artwork in a museum. Collection databases describe, document, and store information about objects, operations, movements and provenance, to name but a few. With such a rich view into the past, present, and maybe even future of a museum, a database is much more than an information storage space for individual staff members and researchers in a museum. It gives us a detailed perspective on the museum as a continuous entity; the study of such databases can not only give insight into a digital art history but, moreover, about institutional and collection history. This paper outlines the use of data in the museum context and describes how data visualization, design, and art can bring new forms of access and comprehension about museum data to a diverse audience.
State of the Art in the Field
“The British Museum computerization of records began in 1976” (Szrajber, 1989), which means that the digitization of museum data has a long-standing history of three main areas: how to store information from a technical and semantic standpoint, how to connect museum data with external institutions, and how to provide access to what kind of data. In the history of digitization in the museum context, we have found many answers to these questions. This paper will introduce the current state of the art in data sharing and linking, data use, visualization and art.
The way we approach museum data can be as manifold as the data itself: scholars access museum information with an inquiry into their field of expertise; public audiences use their personal computers to find information on objects that they would like to see or have seen in the institution; artists study objects’ material context; designers filter objects by color, to name but a few. The methods vary widely, from case studies to large data sorting and analysis processes. One of the premises to use data are the structures that the museums provide. Many online collections provide basic users with an interface that gives a limited view to highly vetted data. Advanced users who want to use, develop, and analyse data need a multi-step approach. First, they need to acquire the data, and at the moment, the most common access points are Sparql endpoints, APIs, and data dumps on repositories such as Github. Next, scholars clean their data in order for them to creatively answer their various questions that they have for the data. This step is crucial to a recursive data-sharing model. Data that has been cleaned, sorted, and documented (noting any missing data, for instance) can be offered back to the museum. Institutions are sharing their data, but they seldom consider taking cleaned, used, and developed data back from their users. This is a missed opportunity.
Digital Humanities in the Museum Context
Scholarship regarding museum data is grounded foremost in disciplines of the humanities and social sciences: the sociology of art considers the social worlds that construct a discourse of art and aesthetics; closely related to it is the social history of art, which is concerned with the social contribution to the appearance of certain art forms and practices; economics and art business, which explores global economic flow and the influence of wealth and management strategies on art; art theory, which concerns the developing discourse on concepts relating to a philosophy of art, and therefore, closely related to curating and art criticism; and art history with research in provenance, image analysis, and museum studies. Researchers in these disciplines work with various methodologies such as qualitative and quantitative methods, hermeneutics, iconography, and aesthetics of reception, depending on their research focus, discipline, and data type.
Interdisciplinary approaches between the aforementioned disciplines and IT emerged in the past decade due to the many digitizing projects of the digital humanities:
With the migration of cultural materials into networked environments, questions regarding the production, availability, validity, and stewardship of these materials present new challenges and opportunities for humanists in contrast with most traditional forms of scholarship, digital approaches are conspicuously collaborative and generative, even as they remain grounded in the traditions of humanistic inquiry, this changes the culture of humanities work as well as the questions that can be asked of the materials and objects that comprise the humanistic corpus. (Burdick, Drucker, Lunenfeld, Presner, Schnapp, 2012).
The Interdisziplinärer Forschungsverbund Digital Humanities (IFDH) in Berlin summarizes two concerns of the discipline, namely the availability and archiving of digital data and teaching, and further education about digital humanities (DH). The analysis of cultural data based on computational methods dates back to the beginning of the discipline with research groups such as “Computers and the History of Art” founded in 1985 and theorists such as Lev Manovich, who coined the term, “digital art history” and approaches the analysis of “cultural data” mainly through quantitative methods such as network analysis and media visualization and who wrote in 2015:
Will art history fully adapt quantitative and computational techniques as part of its methodology? While the use of computational analysis in literary studies and history has been growing slowly but systematically during the 2000s and first part of 2010s, this has not yet happened in the fields that deal with the visual (art history, visual culture, film, and media studies). (Manovich, 2015).
Up to this day, the majority of research projects in the digital humanities and museum context are based on quantitative methods, when the outcome of the project are digital data visualizations. A majority of tools in digital data analysis were developed for automated, algorithmic analysis in the so called “STEM” fields (science, technology, engineering, and mathematics) (Borgman, 2015), with a focus in statistics, geo-mapping, network analysis, or Natural Language Processing, to mention but a few.
The Five Stars of Open Data
For those wanting to use collections data for visualization or computation, it quickly becomes apparent that these data are available in a multitude of structures and formats including text-based downloads, individual systems-based APIs, linked data and even simply as Web pages. Each of these access formats has pros and cons for both the dataset user and its producer. To make sense of these levels of access, Tim Berners-Lee, an inventor of the World Wide Web, calls for a 5-star deployment spectrum of open data, according the following hierarchy:
★ Make your stuff available on the Web (whatever format) under an open license
★★ Make it available as structured data (e.g., Excel instead of image scan of a table)
★★★ Make it available in a non-proprietary open format (e.g., CSV instead of Excel)
★★★★ Use URIs to denote things, so that people can point at your stuff (Linked Data)
★★★★★ Link your data to other data to provide context (Hausenblas, et al., 2015)
Museums providing access to their data run the gamut across this spectrum from one-star collections online to five-star linked open data (LOD) sets. Does more stars mean better data? As data producers, should we be striving for the highest level of this hierarchy, five-star linked open data? The short answer should probably be: It’s complicated. In theory, linked open data yields most overall benefits for connecting across collections and with non-museum data sets from across the Web for modeling, visualizing, and querying purposes. But, in practice, deployment and usage hasn’t reached a critical mass and still suffers from a lack of tools. The GLAM sector has been exploring linked open data for quite some time, including deployments from organizations, such as Europeana and consortia such as the American Art Collaborative, but these use cases have yet to demonstrate a transformative value to research and exploration. This is not to diminish these good efforts as there seem to be a few factors that hinder the growth of access to linked open data sets in the museum sector:
From Relational to Semantic
Most museum collection management systems (CMS) are relational databases, which means that they consist of a series of files linked through related fields. Due to their structure and nature, these relational systems more naturally export as the flat files of the two-star open data variety. Semantic data are structured based on relationships and stored in what’s called a “graph database.” Relationships in the graph database are structured as “triples” that resemble the semantic structure of a sentence with a subject-verb-predicate (the triple) relationship. Relational data from the CMS need to be transformed into semantic triples. This isn’t that difficult in that, often, data in the CMS actually indicates relationships, which allows for this mapping, but it can be tedious work to identify the semantic relationship model and then map fields for transformation. In short, it is a ton easier to make a flat file download.
The Best Part about Standards is That There are a Lot of Them.
Linked Open Data relies on using standards, ontologies, and vocabularies built to designate Universal Resource Identifiers (URIs) that allow data from different sources to be recognized and linked. This poses several challenges to the adoption of linked open data. First, selecting standards and vocabularies would seem straightforward for museums since the CIDOC-CRM ontology has been available for cultural heritage collections cataloging more than ten years. The CIDOC-CRM is:
. . . intended to be a common language for domain experts and implementers to formulate requirements for information systems and to serve as a guide for good practice of conceptual modeling. In this way, it can provide the ‘semantic glue’ needed to mediate between different sources of cultural heritage information, such as that published by museums, libraries and archives. (CIDOC, n.d.).
The American Art Collaborative (AAC), a cohort of 14 museums dedicated to expanding the use and availability of linked open data, found that an ontology such as the CIDOC-CRM while being a natural fit for the modeling of collections data according to semantic format, allowed for so many nuances that each data provider could apply it differently. This led to time-consuming decision-making during the modeling process, as well as complexities in linking similar information that had been modeled according to different nuances. Therefore, the AAC and others in the cultural heritage community developed a target model, called “Linked Art,” which is a subset of CIDOC-CRM, intended to limit inconsistencies in cultural heritage mapping. (American Art Collaborative, 2018). The Linked Art target model, still in a beta version, consists of CIDOC-CRM as the core ontology, Getty Vocabularies as the core sources of identity, and JavaScript Object Notation for Linked Data (JSON-LD) as the primary target serialization. Primary goals of this target model are ease of standardization among museums and ease of usability. (Linked Art, n.d.)
Even with the emergence of the Linked Art target model, there are other competing models, such as the Europeana Data Model (EDM) and other models used across the Web, such as Wikidata, which is much less structured due to its grass-roots crowdsourced origins. These are not either/or propositions necessarily, but this level of decision-making and reconciliation of the museum data can be complex.
Making Something Useable
Many museums, libraries, archives, and digital humanities projects have made positive inroads toward a move to linked open data (LOD). This behind-the-scenes work of transforming, modeling, and defining standards is vital, but the public-facing portions of these projects have received much less development and discussion. This is likely due to the relative complexity outlined above, and a narrow early-adopter audience willing to deal with user interfaces that are not broadly user-friendly or intuitive. There has not been a systematic study of user-interface needs and how different types of people could make use of these linked data sets. Making access to this type of data more intuitive and user-friendly could transform scholarly inquiry using cultural collections. To fully extract the benefits of data-publishing efforts, the field must also approach LOD using user-experience design methodologies.
Changing Mindsets
In 2013, Michele Barbera published the article, “Linked (Open) Data at Web Scale: Research, Social and Engineering Challenges in the Digital Humanities.” Barbera states:
If Linked Data is to be exploited at its full potential, a profound cultural shift needs to occur in the way data is produced, managed and disseminated. This is especially true in the cultural heritage and digital humanities domains, where a strong tradition of two-dimensional, paper-like thinking is still predominant . . . Unfortunately, the research community has not yet been able to leverage this potential within the industry to build production-ready tools easily usable by end-users.” (Barbera, 2013).
This statement perhaps presents that mindset is the true barrier to producing and using linked open data, and perhaps, in using our collections as data more generally.
Barbera concludes, “The time has come to invest in innovation in order to be able to transform the enormous knowledge accumulated through research and the large amount of data recently produced/liberated into a virtuous circle able to generate a self-sustaining and evolving ecosystem.” (Barbera, 2013). Though this article was published five years ago, the state of the field has not changed significantly.
The Case for Linked Open Data at the Georgia O’Keeffe Museum
After outlining many of the challenges of producing and using linked open data, you may wonder why anyone considers going for the five star category of data. Knowing all of the challenges, the Georgia O’Keeffe Museum still decided to embark on a project to publish data from our art, archive, and library collections as linked open data.
The O’Keeffe’s digital infrastructure strategy focused on meaningfully unifying data from the Museum’s distinct data management systems such that new connections could be discovered among those data. Choosing to use a semantic linked data model adhering to museum standards, some well-established and others emerging, made the project in some ways more complex than initially envisioned. But, by thinking of the project within the field-wide context of collections data access, it became a priority to make it possible to not just link data points within this one museum—but to prepare data to be shared and interoperable as part of a larger network of museum and non-museum data throughout the world. This is specifically important to the O’Keeffe since other institutions have significant holdings of the artist’s artworks and related archival collections. With this bigger picture determining the agenda, the O’Keeffe adopted a plan that would approach the project by modeling the data from its systems into linked open data using the “Linked Art” target model, following in the footsteps of the American Art Collaborative. As a small/medium-sized museum, the team felt that it was important to show that museums of this smaller scale could participate in establishing appropriate standards and that the benefits would be substantial for access to knowledge regarding Georgia O’Keeffe.
But even as the O’Keeffe has completed the modeling of its data, questions remain as to its usability, and the museum will attempt to use this linked open data as a platform to explore more user-friendly access. The private sector continues to advance its thinking about how to make use of this knowledge. In 2016, Mike Atherton, a content strategist at Facebook London, published a talk from the UXLx: User Experience Lisbon conference titled, “Designing with Linked Data,” in which he discusses experience design at Web scale, advising that one think not only in terms of “customers” but also of how an organization’s data publication benefits the Web as a whole. He addresses the future of knowledge sharing, connecting with people, and then connecting them seamlessly to information.(Atherton, 2016). For linked open data to be viable, the field needs more focused attention on user experience and access to unlock these connections and relationships across the Web.
Being Opportunistic, with a Critical Eye
Users of collections as data don’t always get to decide the star level of the data, how messy or incomplete it might be, etc. The user needs to be opportunistic, creative, and and willing to work with the messy bits in data and how it is provided, in order to interrogate and tell the stories in the most efficient way possible. The data-curious can build their literacy with smaller, easily understandable data sets before tackling more complex linked data sets. There are a multitude of issues for consideration beyond the five-star deployment—embedded colonized patterns, data sovereignty (especially in terms of indigenous autonomy), and the provenance of data. When approached with a critical eye, the data itself can be used to interrogate its own gaps and flaws.
Visualizing Museum Collections
When institutions make their data accessible, design can help greatly to guide users through a process that can start with a simple query or object search to acquiring raw data for computational utilization. User interfaces that allow museum audiences to explore museum data, bringing a surplus to a simple query-answer scenario, contextualize objects alongside a certain logic of collections. An outstanding example for this is “The Vikus Viewer” (Glinka, Pietsch, and Dörk, 2014-2017) by the Urban Complexity Lab at FH Potsdam. Rather than displaying information of a specific object singled out of their data context, this tool displays each object along time, texture, and themes within its data environment.
In a recent project titled Activating Museums’ Data for Research, Scholarship, and Public Engagement, a consortium of provenance researchers of the translocations Cluster at the TU Berlin, engineers and social scientists of the medialab at SciencesPo and designer and data artists of The Center for Data Arts at The New School, started to develop tools and new methods that focus on design for accessing and displaying museum data. The project is a continuation of data sprints in which about 25 scholars from the mentioned fields work for one week with museum staff to develop prototypes for new software tools. One example is a prototype that was developed in 2017, with live data coming from the entire database of a French museum, showing every operation that has been done with/on an object in the collection. The museum identified 25 different types of operations with subcategories and operations—everything from moving, cleaning, restoring, or exhibiting an object to crating, storing or inspecting it. Rather than accessing an object by its cataloguing details, the prototype displays “the life of the artwork in a museum” in a timeline that can be sorted and filtered with these functions: differentiation between on display/off display; sorting system (frequency of operations, time on/off display) for multiple operations at the same time; filtering system (artist name, title, types/sub-types, artwork domains, selection of time period) for multiple operations at the same time; colour coding according to operation types; hovering over of types shows sub-types of operations. The user can ask questions about the movement of the works of art or which are the artworks that are most/less frequently operated upon? Hypotheses can be tested within the visualization tool: Are more active objects exhibited more often? Are paintings better represented than drawings? The prototype makes comprehensible specific lines of investigation, such as the management of “complex artworks” and the exploration of the correlation between the amount of operations they imply, their visibility in exhibitions, and the frequency of their presentation.

Figure 1: The example shows how knowledge about museum data can come not from the study of objects but rather from the collection as an object that is in a constant fluid motion, it can be seen as a “medium of information” (Groĭs, 2018).
Yanni Loukissas describes this approach as “Local Data Design.”
We treat data not simply as evidence that can help us objectively understand some external subject, but as subjects of inquiry themselves. Why are data created in certain ways by one organization and in different ways by another? Why have procedures for generating and managing data changed over time? When used critically, visualization allows us to turn our view back onto the data themselves. (Luther, 2017).
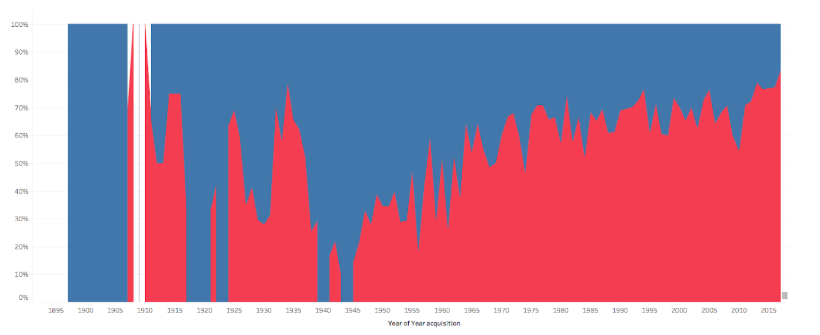 Figure 2: Visualizing museum collections as a whole can give a distant view to detailed inquiries.
Figure 2: Visualizing museum collections as a whole can give a distant view to detailed inquiries.
For the study of object histories, it is significant to understand acquisition policies of the institutions that they belong to. An example is Figure 2, a duo-colored visualization of acquisitions of artists born in the country of the institution (blue) and artists born outside of the country of the institution (red), can give a simple but significant insight into the study of objects and their collection histories. The development of new software tools allows us to ask data collections complex questions and receive answers made visible through design. As shown earlier in the text, as we develop standards and sharing structures, it is possible to reuse, recycle, and rewrite code that was developed for a specific dataset with the intention to be applied in different institutional contexts. Questions about acquisition modes or museum operations can be applied to datasets beyond institutional boundaries. Technical documentation is a key element to share code for other institutional contexts, as shown in the digital humanities project Derrida’s Margins. (Center for Digital Humanities at Princeton, 2018). The data collection is the digitized library of Derrida and images of annotations, which are also cross-referenced in the visualization of this project as citations in his own writings. The data of collection is contextualized in its use case—namely the writing of Derrida. The project is noteworthy because it shows how a well-designed interface makes already cleaned and structured datasets easily accessible and how to cite these datasets in future documentation (Princeton University, n.d.). And again, the users of the library are not confronted with a catalogue of digitized objects but rather access an interface that allows them to explore objects in their specific and complex context.
Data Art
Creative use is one of the great opportunities for museum and cultural heritage data sets. What happens when we think about collection data as a creative medium rather than solely as a reference resource for specialized research?
The distinction between creative use and research use is artificial, but useful. Creative use is open-ended, indeterminate, and instrumental. Like an artistic medium, data is a material that is used in a creative process of exploration. In a research process, a specialist might approach a dataset with a research question in mind to find answers. In a creative process, one might approach a dataset and search for good questions. Creative use opens options and opportunities; it seeks generative juxtaposition, unexpected adjacency and serendipity. It benefits from access to the entire sweep of a collection’s data. Creative use can be undertaken by data artists, designers, poets, performers, digital humanities students, curators, educators.
Following are some examples of creative uses of museum data:
- Performance: Jer Thorp, Ben Rubin and Mark Hansen, A Thousand Exhausted Things. (http://blog.blprnt.com/misc/the-museum-of-modern-art)
- Poetry: Micah Walter, Curatorial Poetry. (http://curatorialpoetry.tumblr.com/about)
- Poetry: Chad Weinard, House of Dust (Remix). (https://house-of-dust.glitch.me)
- Protest art: Guerrilla Girls, Do Women Have to be Naked to Get into the Met. Museum? (https://www.artic.edu/artworks/199773/do-women-have-to-be-naked-to-get-into-the-met-museum)
- Installation: Balboa Park Online Collaborative (Chad Weinard, Jason Alderman and Brinker Ferguson). Self/Reflection. (https://www.bpoc.org/projects/self_reflection)
- Installation: Studio TheGreenEyl. All at Once. (http://www.thegreeneyl.com/allatonce)
- Installation: Rachel Ara, Transubstantiation of Knowledge. (https://www.2ra.co/tok.html)
- Mural: Giorgia Lupi, Data Items: A Fashion Landscape. (http://giorgialupi.com/data-items-a-fashion-landscape-at-the-museum-of-modern-art/)
- Visualizations: Mario Klingeman, The Order of Things. (https://blogs.bl.uk/digital-scholarship/2015/12/bl-labs-awards-2015-creativeartistic-category-award-winning-project.html)
Creative use is not limited to artists outside institutions or short-term artist residencies, however. There is a phase in the process of academic research where a creative process can be used to develop a fruitful research question and direction. Likewise, the curatorial process often starts with a wide-funnel approach, open to suggestions and inspiration provided by new perspectives.
The Pink Art exhibition at the Williams College Museum of Art is an example of creative use of collection data in service of exhibition development. (https://wcma.williams.edu/pink-art/). The exhibition explored the collection through the color pink, with its myriad social associations. The open-ended theme required a new approach and new tools in order to surface unexpected connections and examples. Instead of starting with a checklist based on a curator’s deep knowledge and memory, aided by keyword-driven collection search, the process started with enhanced collection data and visualization. Five algorithms were created (as part of a computer science class) that processed all collection images in order to create ranked checklists of the “pinkest” objects in the collection. Each algorithm “saw” the collection in its own way and provided a new perspective. The rankings informed visualizations that helped curators see “pink” across the collection; data visualization provided a wide view that offered interesting (and often unexpected) inspiration for a final checklist. Pink Art, in its final form in the gallery, was partly a data visualization using collection objects, partly a commentary on curating and coding each as creative processes, and partly a creative work in its own right.

Figure 3: Visualization of the collection of the Williams College Museum of Art, with pink elements highlighted (detail)
Thinking about collection data as a creative medium allows museums to approach their data in a new way. Instead of treating collection data as a reference publication, like a dictionary or a kind of institutional catalogue raisonné, with all the scholarly publication machinery that would entail, the museum can treat the production and refinement of collection data as an ongoing creative practice, acknowledging the contingency and texture of a living data set and embracing the fact that the collection data will never be complete or perfect. (Weinard, 2018).
“WCMA Digital Project” is an example of how this institutional stance toward data as an ongoing creative practice can be operationalized. The Williams College Museum of Art excels at using its collection—and encouraging others to use it (especially faculty and students)—in innovative ways. Whenever a physics professor, for instance, uses a work of art from the collection to teach a science concept, unique new context is generated. The WCMA Digital Project (https://wcma.williams.edu/wcma-digital-project/) seeks to gather that new context, add it to the collection data, and share it, so that others can better use the collection. From an institutional perspective, this generates a dynamic where the everyday operations of the museum—public programs, lectures, classes, etc.—continuously add context to the collection through data.
Seeing collection data as a creative medium affects how data is formatted, publishe and distributed as well. Encouraging creative use means optimizing for the simplest, most portable and most open formats. For collection data, this is almost always a text file, formatted as CSV (comma-separated value) and encoded as UTF-8. These data files can be opened by a simple text editor, manipulated in any spreadsheet application, and imported into more advanced databases and visualization environments. (The JSON format adds capabilities, along with complexity, and an API provides a direct data connection, with a cost of requiring significant technical expertise to utilize.) CSV files can be hosted and distributed via the Web, or via hosted services such as GitHub. Simplicity, flexibility, and interoperability are key for creative use.
Images present a fantastic opportunity for creative uses of collection data. Individual high-resolution images are valuable resources for creative use of collections. While open-access image initiatives are outside the scope of this paper, it is vital to note the increasing importance of collection images as a dynamic dimension of textual collection data. The image-as-data can be processed by algorithms to add visual dimensions like dominant hue, color palette, brightness, contrast to an object record. Further processing can be used to tag content and style, and relate visually similar objects. Not only can collection images be used to augment collection data, they can be used to visualize the collection in creative ways, often using free, open source software. By offering a complete set of collection images—even at thumbnail size—institutions can make it easier for artists, students, designers and others to explore and present the collection in new ways.
Collection data, as a creative medium, provides opportunities for new knowledge and shared authority. When collection data is used in new ways, toward unforeseen ends—as design inspiration, as poetry, as a way to explore neuroscience, or make music—new context is generated. Exploring the data from a new vantage point can uncover areas for improvement or suggest where new fields or formats might be added. New data can be generated, new relationships uncovered. There is then the opportunity to incorporate change into the collection data, to learn and enhance the data, so that when others use the data in the future, the cycle continues. The continuous feedback loop marks a shared authority alongside a unique living data set.
Conclusion
With a long-standing history of digitization and the development of database management systems in the museum context, the field is now at a point where data sharing, linking and use should be considered in any project that makes museum data accessible. The recommendations for the project design of museum data projects are to 1.) consider data access with reference to the – star open data hierarchy (2. to focus on design to guide users beyond a query-answer scenario and to contextualize data and 3.) to give space for creative approaches to data for a recursive involvement of audiences, scholars, and peers.
Our examples were chosen to show that particularly design and data art can lead to transparency and participation in the museum data context. Data improvement with a suggested recursive process can lead to a process-based release of data. The inclusion of peers who develop data use through creative and scholarly uses brings a recursive use and development into the museum context.
References
American Art Collaborative. (2018). “American Art Collaborative Linked Open Data Initiative Overview and Recommendations for Good Practices,” 35.
Atherton, Mike. (2016). “Designing with Linked Data.” Talk given during UXLx—User Experience Lisbon. Accessed July 20, 2018. Available at: https://youtu.be/9Ji3XoaRxLs
Barbera, Michele. (January 2013). “”Linked (open) data at web scale: research, social and engineering challenges in the digital humanities.” JLIS.it. Vol. 4, n. 1. Available at: DOI: 10.4403/jlis.it-6333
Borgman, C. (2015). Big Data, Little Data, No Data. MIT Press, 83.
Burdick, Anne, Drucker, J., Lunenfeld, P., Presner, T., Schnapp, J. (2012). Digital Humanities, Cambridge, Mass: The MIT Press.
Center for Digital Humanities at Princeton University. (2018). “Derrida Documentation.” Derrida’s Margins. Accessed January 30, 2019. Available at: https://princeton-cdh.github.io/derrida-django/
CIDOC. (n.d.) “CIDOC-CRM: Conceptual Reference Model.” Accessed January 30, 2019. Accessed January 4, 2019. Available at: http://www.cidoc-crm.org/
Glinka, K., Pietsch, C., and Dörk, M. (2014-2017). “VIKUS Viewer: Explore Cultural Collections along Time, Texture and Themes.” VIKUS Viewer: Explore Cultural Collections along Time, Texture and Themes. Available at: https://vikusviewer.fh-potsdam.de/
Groĭs, B. (2018). In the Flow. London: Verso, 464.
Hausenblas, M. (2015). “5 Star Open Data.” Accessed January 4, 2019. Available at: https://5stardata.info/en/
“The Interdisziplinärer Forschungsverbund Digital Humanities.” (n.d.) Über den Interdisziplinären Forschungsverbund Digital Humanities in Berlin (if|DH|b). Available at: http://www.ifdhberlin.de/startseite/
“Linked Art Data Model.” (n.d.). Linked Art. Accessed January 30, 2019. Available at https://linked.art/model/
Luther, A. (2017). “Local Data Design: An Interview with Professor Yanni Loukissas.” Data Matters. Accessed January 30, 2019. Available at https://data-matters.nyc/?p=18579
Manovich, L. (2015). “The Science of Culture? Social Computing, Digital Humanities, and Cultural Analytics.” Available at: http://manovich.net/index.php/projects/cultural-analytics-social-computing
Princeton University. (n.d.). “How to Cite ‖ Derrida’s Margins.” Princeton University. Accessed January 30, 2019. Available at: https://derridas-margins.princeton.edu/cite/
Szrajber, T. (1989). CDMS: the computerization of the British Museum Collections. London: Harwood Academic Publishers, 9.
Weinard, C. (2018). “Data as Medium” In M. Walter and M. Ferrucci (eds.). Thoughtforms. New York: Micah Walter Studio. Available at: https://medium.com/@caw_/data-as-medium-361814dba6a9
Cite as:
Neely, Liz, Luther, Anne and Weinard, Chad. "Cultural Collections as Data: Aiming for Digital Data Literacy and Tool Development." MW19: MW 2019. Published February 1, 2019. Consulted .
https://mw19.mwconf.org/paper/cultural-collections-as-data-aiming-for-digital-data-literacy-and-tool-development/